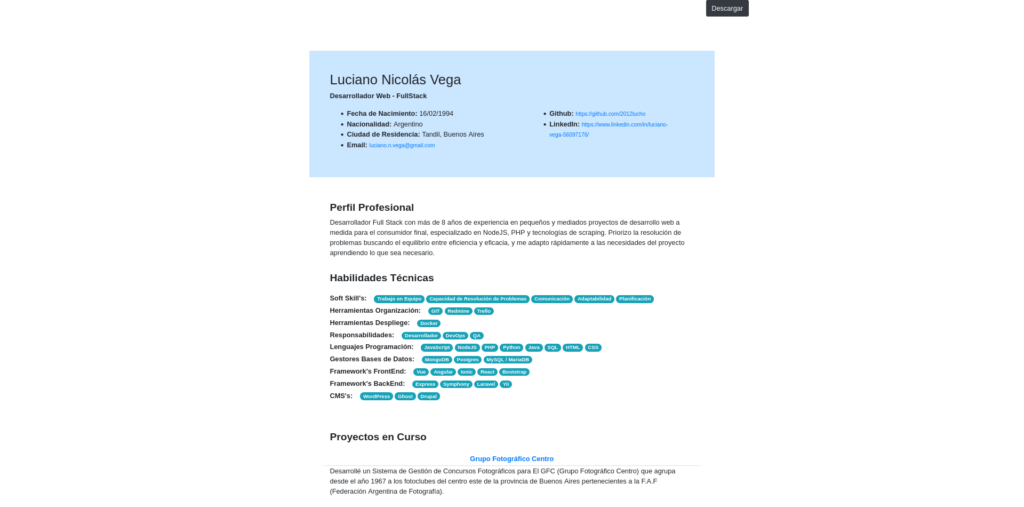
En la actualidad me encuentro con la necesidad de actualizar el porfolio, tener un buen formato de CV adaptable para postularme a ofertas de trabajo o simplemente para resumir mis aptitudes y experiencia.
Por lo que me plantee algunos requerimientos mínimos que el mismo deba cumplir para estar satisfecho y que a su vez sirva a mis objetivos:
Debe:
Tener una versión Web Responsive.
Poder descargarse en formato .pdf.
Ser fácil de adaptar dependiendo al tipo de postulación a la que aspiro.
Tener un formato legible por los sistemas de procesamiento de CV’s de las consultoras.
Ser un diseño simple que pueda ir mejorando a futuro.
Elección de la opción
En si hay muchas opciones viables, la mas sencilla es tener actualizado el perfil de Linkedin para poder descargarlo como .pdf, hay sitios web que asisten a la generación de un formato profesional a partir de plantillas, lo podría diseñar en algún procesador de textos.
Si bien cualquiera de esas opciones son buenas y cómodas, buscaba realizar un pequeño proyecto en el cual en si mismo pueda demostrar mis capacidades y que cumpla con los puntos anteriormente mencionados.
Por lo que decidí hacer un nuevo desarrollo usando VueJS que me permitirá tener total libertad creativa.
Nuevo proyecto VueJS
Cree un nuevo proyecto usando Vue + Vite (disponible en Github) a partir de su configuración inicial, al cual solo agregué el CDN de Bootstrap y la librería jsPDF para la posterior descarga del mismo.
La información propia del CV está definida en un JSON al estilo:
De esta forma puedo tener toda la información cargada y de acuerdo al caso comentar o des-comentar secciones.
Luego se define la estructura de componentes básica agregando un componente por cada sección:
Diseño general
Opté por un diseño minimalista haciendo énfasis en el contenido, priorizando el orden de acuerdo a la importancia de la información, manteniendo la formalidad sin agregados que causen distracción.
Hace un tiempo atras empecé a interiorizarme en el manejo de Web Sockets, para lo cual realizé un chat de pruebas, para lo cual necesité configurar Nginx para que se ocupe de realizar la redirección de puertos y la utilización de certificados SSL.
Bueno, el primer paso será obtener los certificados SSL, para lo cual usé Let’s Encript, luego se necesita crear el archivo de configuración correspondiente en: /etc/nginx/sites-available.
En este caso el archivo que cree se denomina chat-ws.greenborn.com.ar, con el siguiente contenido:
server {
listen PUERTO_ESCUCHA;
ssl on;
server_name DOMINIO;
ssl_certificate PATH_CERTIFICADO/fullchain.pem; # managed by Certbot
ssl_certificate_key PATH_CERTIFICADO/privkey.pem; # managed by Certbot
include PATH_LETS_ENCRIPT/options-ssl-nginx.conf; # managed by Certbot
ssl_dhparam PATH_LETS_ENCRIPT/ssl-dhparams.pem; # managed by Certbot
location / {
proxy_http_version 1.1;
proxy_set_header Upgrade $http_upgrade;
proxy_set_header Connection "upgrade";
proxy_pass "http://127.0.0.1:PUERTO_INTERNO";
}
}
Claramente en el mismo se debe reemplazar:
PUERTO_ESCUCHA: Especificando el puerto que se usará publicamente para la conexion con el Web Socket
DOMINIO: El dominio asignado a la APP
PATH_CERTIFICADO: Ubicación del certificado SSL
PATH_LETS_ENCRIPT: Ubicación de la instalación de Lets Encript
PUERTO_INTERNO: Es el puerto que la APP estará escuchando
Luego será necesario crear el enlace simbólico del archivo de configuración, por ej con:
Con la idea de interiorizarme y aprender sobre los Web Sockets (WS) me decidí a realizar un nuevo proyecto usando NodeJS con framework Express y VueJS para el front.
¿Por que se eligieron dichas tecnologías?
Se optó por usar NodeJS por que tiene un muy buen manejo de WebSockets, ya que con el paquete express-ws podremos realizarlo de forma sencilla, dicho paquete se apoya en el framework Express; el cual me parece atractivo al no obligar al programador a usar un patrón de diseño en específico y es muy liviano.
NodeJS también tiene la ventaja, por sobre PHP, de poder almacenar información en memoria lo que nos permite prescindir de base de datos, ya que PHP al no guardar estados no lo permite y deberíamos encontrar alguna forma de mantener la persistencia de los datos.
El front podría haberlo desarrollado en Angular, framework con el cual vengo trabajando desde ya hace un tiempo, pero en cambio esta vez opté por VueJS, por que el mismo es más liviano, consume menos recursos en proceso de desarrollo (RAM principalmente), las APPs generadas son más livianas.
Y VueJS en si es más sencillo de usar y da menos problemas con respecto al manejo de dependencias, es más debugeable que Angular (aunque Angular mejoró bastante en dicho aspecto en el último tiempo)
Realmente no encuentro motivo para volver a Angular, por lo que Vue ya es mi framework favorito.
Otro punto que para mi suma es el no tener que usar TypeScript lenguaje que no termino de tomar muy en serio por que luego se transpila a JavaScript y para mi el tipado artificial que aplica solo suma una capa más sin aportar mucho, se pueden evitar los problemas de los lenguajes no tipados prestando un poco de atención.
¿Qué módulos conformarán el proyecto?
Como en muchos sistemas webs, el proyecto se dividirá en un Backend, el cual se encargará de proporcionar un endpoint al cual los clientes se podrán conectar por medio de WebSockets, llevará el listado de clientes conectados y retransmitirá los mensajes a todos los clientes conectados.
Y un front que se encargará solo de establecer la conexión e intercambiar mensajes.
El Backend
El código del backend es muy sencillo y de hecho hasta lo tendríamos en un solo archivo server.js:
let express = require('express');
let app = express();
let expressWs = require('express-ws')(app);
let uuid = require("uuid")
require("dotenv").config()
let registro_clientes = []
let reporte_conectados = []
expressWs.getWss().on('connection', function(ws) {
ws['id_conexion'] = uuid.v4()
});
app.ws('/', function(ws, req) {
ws.on('message', function(msg) {
let msgJson = null
try {
msgJson = JSON.parse( msg )
console.log(req.id)
if (msgJson.hasOwnProperty('accion')){
switch(msgJson.accion){
case 'registro':
msgJson.nombre = msgJson.nombre.replace(/]+(>|$)/g, "")
if (msgJson.nombre.length < 4){
ws.send(JSON.stringify({
accion: 'alerta',
msg: 'El nombre de usuario debe tener al menos 4 caracteres'
}))
return;
}
let registro = {
id: uuid.v4(),
nombre: msgJson.nombre,
accion: 'registro',
id_conexion: this.id_conexion
}
//comprobamos que no haya alguien registrado con el mismo nombre
for(let c=0; c < registro_clientes.length; c++){
if (registro.nombre == registro_clientes[c].nombre){
ws.send(JSON.stringify({
accion: 'alerta',
msg: 'El usuario especificado ya existe'
}))
return;
}
}
registro_clientes.push( registro )
reporte_conectados.push( registro.nombre )
console.log('se registro nuevo usuario', registro)
ws.send(JSON.stringify(registro))
let clientes = expressWs.getWss().clients
clientes.forEach(cliente => {
cliente.send(JSON.stringify({
accion: 'mensaje_sys',
msg: registro.nombre + ' Se ha unido a la sala'
}))
})
break;
case 'mensaje':
//comprobamos que el mensaje provenga de un cliente registrado
let encontrado = false
for(let c=0; c < registro_clientes.length; c++){
if (msgJson.autor.id == registro_clientes[c].id && msgJson.autor.nombre == registro_clientes[c].nombre ){
encontrado = true;
break;
}
}
//si es asi lo reenviamos al resto de los clientes
if (encontrado === true){
//se hace sanitizacion
msgJson.texto = msgJson.texto.replace(/]+(>|$)/g, "")
//se hace validacion
if (msgJson.texto.length > 500){
break;
}
let clientes = expressWs.getWss().clients
clientes.forEach(cliente => {
cliente.send(JSON.stringify(msgJson))
})
}
break;
}
}
} catch( error ){
console.log('error', error)
}
});
ws.on('close', function(code) {
console.log('desconectado', this.id_conexion)
let nombre = ''
for(let c=0; c < registro_clientes.length; c++){
if (registro_clientes[c].id_conexion == this.id_conexion){
nombre = registro_clientes[c].nombre
registro_clientes.splice(c,1)
reporte_conectados.splice(c,1)
break;
}
}
if (nombre != ''){
let clientes = expressWs.getWss().clients
clientes.forEach(cliente => {
cliente.send(JSON.stringify({
accion: 'mensaje_sys',
msg: nombre+' ha abandonado la sala'
}))
})
}
})
});
setInterval(()=>{
let clientes = expressWs.getWss().clients
clientes.forEach(cliente => {
cliente.send(JSON.stringify({
accion: 'reporte_online',
reporte: reporte_conectados
}))
})
}, 500)
app.listen(process.env.PUERTO);
console.log('puerto', process.env.PUERTO)
Creo que algo interesante a resaltar es que el manejo de la comunicación se realiza por medio de eventos.
Por ej nos podremos subscribir al evento “connection” que se dispara por cada nueva conexión establecida por el cliente
Este evento lo aprovechamos para poder generar identificadores únicos para cada cliente conectado.
Luego usamos Express como intermediario para atender los WS
app.ws('/', function(ws, req) {
....
Luego podremos atender el evento “message” que se disparará por cada mensaje recibido de algún cliente en particular.
Dichos mensajes usarán el formato JSON, por que creo que es la forma más facil de manejar datos estructurados, que puedan ser codificados y decodificados facilmente.
Y es necesario definir una estructura básica a la información ya que existen varios tipos de mensajes a ser enviados y recibidos.
Tipos de mensajes
reporte_online: Este mensaje se envía de forma períodica a todos los clientes conectados, y se usa para informar sobre los usuarios que actualmente están online, un ej del mismo sería: { “accion”:”reporte_online”, “reporte”: [ “Flor”, “Pepe”, “María”, “Juan” ] }
mensaje_sys: Se trata de un mensaje del sistema, que será mostrado a todos los clientes, se usa para informar por ej cuando alguien ingresa o egresa de la sala, ej del mismo sería: { “accion”:”mensaje_sys”, “msg”: “Flor ha abandonado la sala” }
alerta: Se usa para mostrar alertas o mensajes de error, por ej: { “accion”:”alerta”, “msg”: “El usuario especificado ya existe” }
registro: Se usa para registrar un nuevo usuario, ya que ni bien se ingresa al chat se solicita un nombre de usuario con el cual interectuar, para lo cual en el submit del formulario de nombre de usuario, se envia un mensaje de tipo “registro”, por ej: { “accion”:”registro”, “nombre”: “Pepe” }
mensaje: Se trata de un mensaje en sis mismo enviado por un usuario registrado, un ej: { “accion”:”mensaje”, “autor”: { “id”: “dsafdsfawe5433245-43534w”, “nombre”: “Marta” }, “texto” :”Hola Pepe!” }.
Algunas comprobaciones básicas
Se procede a sanitizar la entrada de caracteres de las entradas tanto al intentar elegir un nombre de usuario como en los mensajes en si mismos.
Excluyendo los caracteres que pudieran corresponder a tags html, ya que la idea es que se utilice solo texto, y quitar algunos caracteres problemáticos.
Si bien luego VueJS en el front por si solo salinitiza los datos para que no se incruste por ej código JS en los mensajes / CSS / HTML, creo que está bueno hacerlo de todos modos.
Para eso basta solo con usar: replace(/]+(>|$)/g, “”)
En el nombre de usuario se establece una longitud mínima del mismo y en el texto de los mensajes una longitud máxima.
Broadcast
Para el envio masivo de mensajes, primero se debe obtener el listado de clientes conectados, el cual se realiza usando:
let clientes = expressWs.getWss().clients
Luego se pueden recorrer los clientes usando un for, por ej:
El frontend en si mismo no tiene mucho, toda la lógica la implementé en un nuevo componente llamado VentanaChat.
El cual se encarga de establecer la conexión e intercambiar mensajes.
Para realizar la vista usé Bootstrap ya que creo que el framework de estilos más facil de usar, además existe el packete Bootstrap-vue3 que lo implementa y provee los componentes bàsicos para ser facilmente utilizable en Vue.
El establecimiento de la conexción con el WebSocket, que se realiza con:
conexion.value = new WebSocket( process.env.VUE_APP_API_URL )
Muy facil, no?
El “process.env.VUE_APP_API_URL” hace referencia a la variable VUE_APP_API_URL definida en un .env del proyecto, que se usa para poder configurar facilmente la url del endpoint
Y luego se atienden los eventos con:
conexion.value.onmessage = function(event) {
El proyecto en ejecución
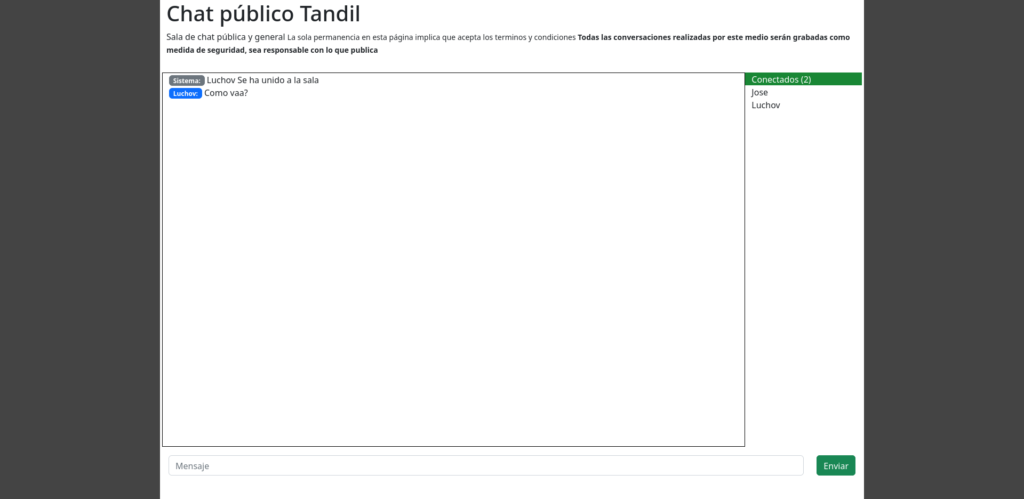
Una vez que esten levantados tanto el back como el front, en el navegador lo podremos ver de la siguiente forma:
Se presentaron algunos problemas al intentar montar la demo, ya que fue necesario configurar Nginx para redireccionar un puerto y poder usar certificados SSL con la comunicación con el WebSocket, algo que trataré en un post aparte.
En esta oportunidad, la idea es ir un poco más allá y empezar a realizar un análisis sobre los mismos.
Ya que por el momento tengo más de 50 MB de logs de autenticación (descomprimidos).
¿Que se pretende analizar?
Por lo pronto hacer una estadistica de la cantidad de indidencias por IP.
Para lo cual usaré un pequeño script en Python que se encargará de recorrer los archivos (que serán almacenados en un directorio “logs”) y generar el .CSV con el resultado del reporte que se guardará en la carpeta “resultado”.
También se publicará el listado de IPs con su correspondiente numero de intentos por si a alguien le sirve, aunque lo más probable es que aquellos que quieren ingresar sin credenciales de acceso ya tengan IPs diferentes salvo que el mismo se realice desde servidores especificos que ya fueron vulnerados.
Y si uno tiene contratado un server con una IP que se encuentre en dicha lista, y no se dedica a realizar dichas actividades, debería revisar su sistema a fondo por que es claro que están usando su equipo sin su consentimiento.
¿Como se hace el análisis?
Como se mencionnó anteriormente, usando Python3 y las librerías os y csv.
Con la librería os se puede obtener el listado de archivos de una carpeta, para lo que nos bastaría una linea como la siguiente:
lista_archivos = os.listdir("logs")
Luego realizo una función que se encarga de recorrer cada una de las lineas de los archivos cargados:
def procesar_log( nombre_archivo ):
archivo = open(nombre_archivo, mode="r")
for linea in archivo:
split_linea = linea.split(":")
fecha = split_linea[0].split(" ")
mes = fecha[0]
dia = fecha[1]
hora = fecha[2]
minuto = split_linea[1]
split_linea_2_s = split_linea[2].split(" ")
segundo = split_linea_2_s[0]
host = split_linea_2_s[1]
app = split_linea_2_s[2]
app_split = app.split('[')
prioridad = ''
if len(app_split) == 2:
app = app_split[0]
prioridad = app_split[1].split(']')[0]
len_s_linea = len(split_linea)
c = 4
mensaje = split_linea[3]
while c < len_s_linea:
mensaje = mensaje + ':' + split_linea[c]
c += 1
primera_palabra = mensaje.split(" ")[1]
#Buscamos IPs IPv4
mensaje_ip4 = get_ipv4(mensaje)
#Armamos el registro
registro = { "fecha":[mes, dia], "hora":[hora, minuto, segundo], "ip": mensaje_ip4, "primera_palabra":primera_palabra, "mensaje":mensaje }
#Catalogar por primera palabra del mensaje
if not primera_palabra in logs_palabra:
logs_palabra[ primera_palabra ] = []
logs_palabra[ primera_palabra ].append(registro)
#Catalogar por ipv4
if mensaje_ip4 == '':
mensaje_ip4 = 'sin_catalogar'
if not mensaje_ip4 in logs_ip:
logs_ip[ mensaje_ip4 ] = []
listado_ips[ mensaje_ip4 ] = { "cant_intentos": 1 }
else:
listado_ips[ mensaje_ip4 ][ "cant_intentos" ] += 1
logs_ip[ mensaje_ip4 ].append(registro)
#Catalogar por fecha y hora
if not mes in logs_fecha_hora:
logs_fecha_hora[mes] = {}
if not dia in logs_fecha_hora[mes]:
logs_fecha_hora[mes][dia] = {}
if not hora in logs_fecha_hora[mes][dia]:
logs_fecha_hora[mes][dia][hora] = {}
if not minuto in logs_fecha_hora[mes][dia][hora]:
logs_fecha_hora[mes][dia][hora][minuto] = {}
if not segundo in logs_fecha_hora[mes][dia][hora][minuto]:
logs_fecha_hora[mes][dia][hora][minuto][segundo] = []
logs_fecha_hora[mes][dia][hora][minuto][segundo].append(registro)
archivo.close()
Basicamente se usa el metodo split para separar cada una de las lineas del archivos y poder procesarlas.
Y guarda la información en los objetos:
logs_palabra: Donde los registros se catalogan de acuerdo a la palabra con la cual empiezan
logs_fecha_hora: Para catalogar los registros por fecha
logs_ip: para catalogar los registros por IP
listado_ips: Se genera un listado de IPs al cual se le asigna la cantidad de veces que una ip aparece en un registro
Para obtener la IPv4 a partir de un texto uso:
def get_ipv4( text ):
ip = ''
numero_grupo = ''
caracter_anterior = ''
cant_puntos = 0
c = 1
len_text = len(text)
if len_text > 0:
caracter_anterior = text[0]
while c < len_text:
if text[c].isnumeric():
numero_grupo += text[c]
elif text[c] == '.' or (text[c] == ' ' and caracter_anterior.isnumeric() and cant_puntos < 4):
cant_puntos += 1
if numero_grupo.isnumeric() and int(numero_grupo) < 256:
ip += numero_grupo
if cant_puntos < 4:
ip += '.'
numero_grupo = ''
caracter_anterior = text[c]
c += 1
if cant_puntos == 4:
return ip
else:
return ''
Entonces luego se recorre el listado de archivos de logs para llamar a la función que se encarga de cargar datos en los arreglos con:
for archivo in lista_archivos:
print('procesando archivo: '+archivo)
procesar_log("logs/"+archivo)
Y luego de tener listo el arreglo (ya se que no son arreglos, son diccionarios, pero por lo pronto los llamo así) listado_ips se procede a armar el .csv
with open('resultado/ips.csv', 'w') as csvfile:
filewriter = csv.writer(csvfile, delimiter=',', quotechar='|', quoting=csv.QUOTE_MINIMAL)
filewriter.writerow(['IP', 'Cantidad registros'])
for ip in listado_ips:
print(ip + ' > ' + str(listado_ips[ip]["cant_intentos"]))
filewriter.writerow([ip, listado_ips[ip]["cant_intentos"]])
Consideraciones sobre el código anterior
Uno podría preguntarse para que definir los diccionarios: logs_palabra, logs_fecha_hora y logs_ip si tienen información redundante y no se estan usando ahora!
La respuesta a esa hipotética pregunta es simple, pienso usarlos mas tarde por que pienso agregar más funcionalidades al script.
Otra cuestión a tener en cuenta es que la función que obtiene la IP no toma en cuenta algunas cosas como por ej los puertos, o que solo esté pensada para IPv4, cuando hace mucho tiempo IPv6 ya està entre nosotros.
Por lo pronto no llegaron peticiones con IPv6 asignadas creo que es interentarse preguntarse el por qué, así que por eso todavía no las consideré.
Los registros que dicen “sin_catalogar” corresponden a registros que están relacionados a una de las incidencias pero en los cuales no figuran un IP en específico, por lo cual no los inclui para no inflar las estadisticas, ya que por cada intento de inicio de sesión se crean al menos 4 registros.
Conclusiones
Creo que no podría terminar el post sin un gráfico, por lo que realizé uno a partir del .csv:
En si, intentando ser objetivo no nos daría mucha información, ya que sería necesario cruzar otros datos para poder identificar mejor la procedencia de los intentos de inicio de sesión, ya que quien quiera ingresar puede que use varias IPs diferentes.
Creo que las únicas certezas que podemos tener sobre los mismos por el momento, es que un aproximado de un 10% de las mismas se están realizando de forma automatizada con algún script o herramienta, ya que nadie en su sano juicio probaría más de 300 claves de forma manual.
Este gráfico más que certezas me dejan preguntas para seguir investigando…
A veces no queda otra que aplicar parches horribles para solucionar alguna situación que de otra forma o se gasta mucho tiempo o en cambio no hay forma de hacerlo de manera prolija.
Esta vez al parecer se trata de la segunda opción :(.
El error en cuestión
Básicamente ocurre que cuando Yii lanza una excepción con un código de error, por ej 5xx, 4xx en los encabezados de la petición no se retornan los headers correspodientes al CORS.
Lo que da como resultado que el navegador indique un error como el siguiente:
Lo que en mi caso particular, en Angular (asumo que también debe ocurrir con otros frameworks y librerías).
No permite obtener correctamente los códigos de error en los interceptores y cualquier petición.
Lo que es importante para diferenciar los errores retornados de algún endpoint, de las fallas de autenticación.
Ya que si se obtiene un código 401, el comportamiento esperado sería poder dirigir al usuario a la página de login.
Y en caso de otro tipo de error, mostrar un mensaje aclaratorio correspondiente.
Como no se pudo solucionar
Lo primero que intenté fue modificar el archivo de configuración de Nginx para asegurarse que siempre se agreguen los headers CORS, de forma similar a como se hace en el caso de archivos de imágenes y otros documentos estáticos.
Pero no funcionó, ya que el Access-Control-Allow-Origin se sobrescribía con un valor inválido.
Como si se soluciono
Des pues de buscar un tiempo en internet me encontré con un post que lo explicaba y que también hizo la prueba modificando la configuración del server.
La solución obtenida hasta el momento es editar directamente un archivo del core del framework
Por lo que localizaremos: vendor/yiisoft/yii2/filters/auth/AuthMethod.php
Y en dicho archivo buscar el método: handleFailure
y dejarlo así:
public function handleFailure($response)
{
header('Access-Control-Allow-Origin: *'); //no queda otra por el moemnto
header('Access-Control-Allow-Headers X-Requested-With,Content-Type,x_requested_with');
throw new UnauthorizedHttpException('Your request was made with invalid credentials.');
}
Tal vez luego encuentre alguna solución más elegante, pero por ahora es una escusa para inaugurar una nueva etiqueta #CrotingPrograming!
Una vez guardado, llega la hora de la verdad, y haciendo un console.log del error:
Aparece como debe ser, ¡Que hermosa es la vida!
Que habría que hacer?
Sin dudar reportarlo a la policía del Web Development y de ahí insistir a ver si lo solucionan o proponer una mejor solución en los canales oficiales, por que en la última versión al día de la fecha no es algo que se haya arreglado.
Quiero guardar esta chanchada en mi repo, ¿Que hago?
Fácil, agregamos una excepción en el .gitignore
!vendor/yiisoft/yii2/filters/auth/AuthMethod.php
y si aún así se resiste, se puede usar el comando:
Hace unos días estuve hablando con un posible cliente sobre la posibilidad de realizar un pequeño juego de preguntas y respuestas que sería usado en el marco de una exposición.
Al final dicho proyecto no prosperó, por que luego no volví a ser contactado, pero de todas formas me parecía una buena escusa para realizar un pequeño proyecto en Phaser Framework.
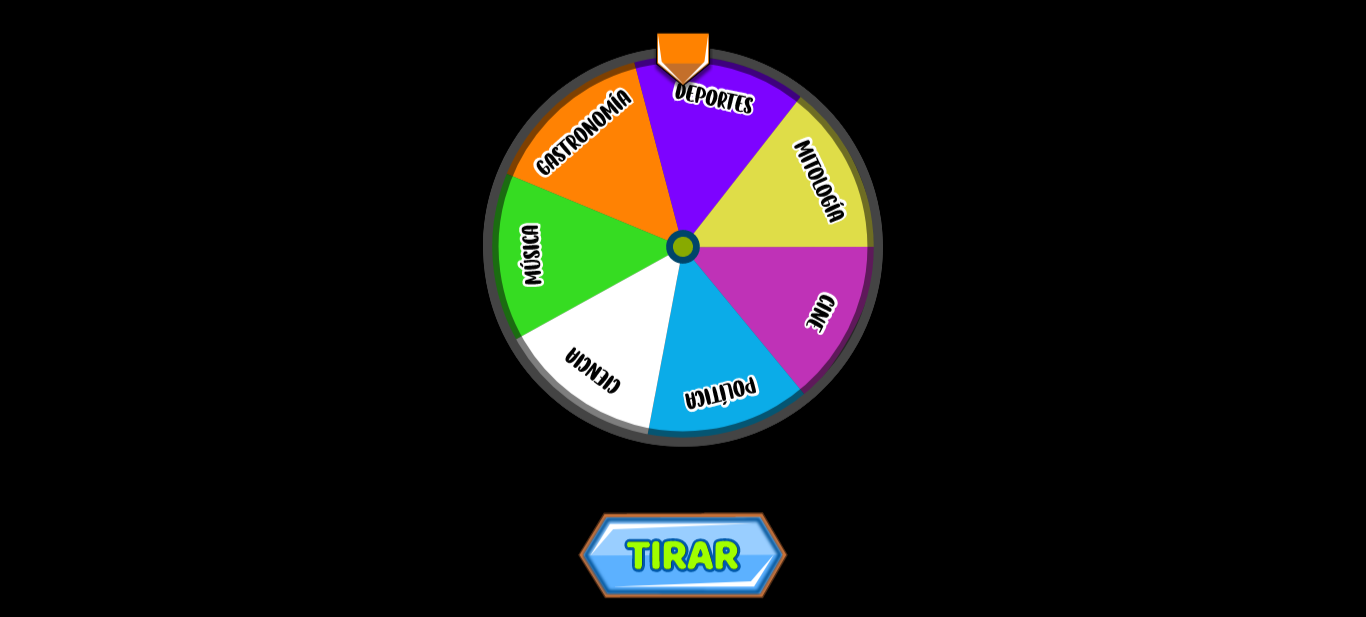
El juego se puede dividir en 3 vistas o escenas, en la primera contamos con una ruleta que se acciona con un botón, la cual al detenerse se selecciona una categoría luego de lo cual se pasa a la siguiente escena.
En donde se presenta una pregunta al azar correspondiente a la categoría seleccionada con 4 posibles respuestas, una vez seleccionada la respuesta, se pasa a la siguiente escena.
La cual muestra si la pregunta se contestó de forma correcta y el detalle de la respuesta, luego de lo cual se vuelve a la pantalla inicial.
La estructura del proyecto
La estructura básica de archivos y directorios que definí para el juego fue la siguiente:
Assets
audio
bien1.mp3: Respuesta correcta
click1.mp3: Sonido de ruleta.
mal1.mp3: Respuesta incorrecta
wclick1.mp3: Botón presionado
imagen
areapreg.svg: Fondo para texto de pregunta
b1.svg – b4.svg: Botones para elegir opción.
btn_sig.svg: Botón siguiente.
btn_tirar.svg: Botón para girar ruleta.
ruleta.svg: Imagen de la ruleta.
select_ruleta.svg: Imagen del selector de categoría.
js
boton.js: Usado para definir el comportamiento de todos los botones.
display.pregunta.js: Define el comportamiento del display de preguntas.
elemento.juego.js: Código común a todos los elementos del juego.
general.js: Usado para definición de funciones auxiliares, como la de conversión de ángulos.
listado.preguntas.js: La lista de preguntas en si misma.
pantalla.preguntas.js: Se define el comportamiento de la vista de pregunta.
pantalla.respuestas.js: Define el comportamiento de la vista de respuesta.
pantalla.ruleta.js: Define el comportamiento de la vista de la ruleta.
principal.js: Crea la instancia general del juego, define las vistas y gestiona la precarga.
puntuador.js: Por ahora no se usa, a futuro para manejar puntajes.
ruleta.js: Define el comportamiento de la ruleta.
index.html: Importa todos los scripts.
La ruleta
La ruleta consiste en una imagen circular, y al igual que el resto, se trata de una imagen vectorial.
Las categorías están definidas en un arreglo de configuración, de la siguiente forma:
Estando ordenadas de forma antihoraria con respecto a como se definen en la imagen, el parámetro color e id los agregue pensando a futuro, ya que por el momento están hardcodeadas, pero si a futuro hago un backend en donde puedan definirse las mismas, son parámetros necesarios.
La aleatoriedad
Para que la misma se detenga en cada tirada en una posición diferente, definí dos propiedades: aceleración y velocidad que toman valores aleatorios con cada tiro.
El efecto de giro por el cual comienza girando rápido y luego reduce su velocidad hasta detenerse, no es algo complicado, por ejemplo por cada frame se ejecuta el siguiente código:
update(){
this.phaserSprite.angle += this.velocidad;
this.velocidad += this.aceleracion;
if (this.velocidad < 0){
this.velocidad = 0;
if (!this.resultado_entregado){
this.resultado_entregado = true;
this.ultimo_resultado = this.getResultado();
this.ultima_pregunta = this.listado_preguntas.getPregunta( this.ultimo_resultado );
this.callback_resultado();
}
} else {
//Se hace el sonido de la ruleta
this.click_cnt = Math.round(this.phaserSprite.angle/this.intervalo_subdivision);
if (this.click_cnt != this.click_cnt_ant){
this.click_cnt_ant = this.click_cnt;
this.juego.sound.play('click_ruleta');
}
}
}
Obtención del resultado
El resultado de la categoría en la cual se detiene la ruleta se obtiene por medio del ángulo en la cual queda al detenerse, el único problema al que me enfrenté es que Phaser define el valor del ángulo de los sprites entre 0 y 180 y luego entre -180 y 0, cuando lo lógico ubiera sido que el mismo se defina entre 0 y 360.
Para suplirlo agregué un par de funciones que se encargan de convertir el valor de los ángulos:
function anguloComunAPhaser( angulo ){
if (angulo > 180){
return 360 - angulo;
}
return angulo;
}
function anguloPhaserAComun( angulo ){
if (angulo < 0){
return angulo + 360;
}
return angulo;
}
Para saber en que valor de ángulo comienza y finaliza la categoría, luego de crear la ruleta agregué un for que se encarga de definir los valores de los mismos en el arreglo de categorías:
this.intervalo_subdivision = 360/this.config.categorias.length;
//Se asignan los valores de angulos a las categorias
//Se usan angulos de 0 a 360 como seria lògico
for (let c=0; c < this.config.categorias.length; c++){
this.config.categorias[c].a_i = c*this.intervalo_subdivision;
this.config.categorias[c].a_f = (c+1)*this.intervalo_subdivision;
}
Por lo que una vez que ya están definidos dichos valores, la categoría se obtiene facilmente:
getResultado(){
//Se le suma 90º por que el selector esta arriba, no a la derecha de la ruleta
let pos = anguloPhaserAComun( this.phaserSprite.angle + 90 );
this.ultimo_resultado = null;
for (let c=0; c < this.config.categorias.length; c++){
if ( numeroEntre(pos, this.config.categorias[c].a_i, this.config.categorias[c].a_f) ){
return this.config.categorias[c];
}
}
return null;
}
Allí también llamo a una función que se encarga de verificar si el angulo obtenido se encuentra entre dos números sin importar si num1 es mayor a num2 o viceversa (inicialmente la definí así por la forma en la que Phaser define los ángulos):
function numeroEntre(n, num1, num2){
if (num2 < num1){
let aux = num2;
num2 = num1;
num1 = aux;
}
if (n >= num1 && n <= num2){
return true;
}
return false;
}
Obtención de la preguntas:
Las preguntas por el momento están definidas en un arreglo, también hardcodeadas como las categorías, aunque a futuro podría guardarlas en una base de datos y consultarlas vía API.
Creo que lo único interesante de las mismas es que para hacer que no se repitan lo más simple fue borrarlas del arreglo cada vez que saliera una nueva elegida.
Mostrar mensajes de error con alerts, no es lo mejor, por que por ej si el usuario los tiene deshabilitados nunca se podrán ver y por que no son personalizables y el navegador decide que mostrar.
Por lo cual hoy actualicé el código para reemplazar dichos mensajes por un modal que indica el error en si.
Anteriormente también se agregaron los metatags de OpenGraph para que pudiera mostrarse una mejor previsualización del enlace al compartirlo.
Una recomendación mínima para contar con un login más seguro consiste en deshabilitar la posibilidad de ingresar directamente con el usuario root, crear un nuevo usuario con su respectiva clave .pem y no usar el puerto por defecto para la conexión SSH.
De hecho lo mejor sería, en caso de que varias personas necesiten realizar tareas en el server, que cada uno tenga su respectivo usuario y contraseña.
En muchas ocasiones lo usual, luego de contratar un VPS, Cloud Server o dedicado, es que el mismo solo proporcione acceso root.
Por lo que la primera tarea consistirá en crear un nuevo usuario, que será el que luego se usará para conectarse por SSH.
Crear un nuevo usuario
Bien, ahora crearemos un nuevo usuario, en este caso el mismo será una sucesión de letras minúsculas al azar (puede usar nuestro generador de contraseñas para dicho propósito).
Podriamos usar jazmin, juan, lucrecia, pepe, pero esta bueno hacer las cosas un poco más difíciles para quien quiera entrar probando nombres al azar.
Para eso bastará con usar el comando:
# adduser njisxyoifwrkttwabyfx
En los nombres de usuario, por defecto no se permiten mayúsculas o símbolos, por cuestiones relacionadas al sistema de directorio (por ej si se crea la carpeta del mismo dentro /home/) o a scripts del sistema o propios que operen con nombres de usuario.
Luego de ejecutar dicho comando, el sistema te pedirá el ingreso de una nueva contraseña, en este caso se permite tanto mayúsculas, minúsculas y una gran cantidad de símbolos, por lo que podemos ser creativos.
Luego nos pide información básica de contacto, esto lo podremos dejar vacío o completar con cualquier cosa.
En este momento podemos intentar ingresar con:
$ ssh njisxyoifwrkttwabyfx@IP_server -p MI_PUERTO
Modificar el archivo de configuración del servidor SSH
Con el editor Nano, se modificará el siguiente archivo:
# nano /etc/ssh/sshd_config
Deberemos buscar las lineas
Port 22 - Modificar el puerto por defecto
PermitRootLogin no
X11Forwarding no
PermitEmptyPasswords no
AllowUsers njisxyoifwrkttwabyfx - Para solo permitir el ingreso del usuario
Estas son las configuraciones mínimas, luego dependiendo el caso se pueden modificar otras opciones.
Guardamos y pasamos al siguiente paso.
Actualizar reglas del Firewall
Se asume que usa ufw como firewall, por lo que el primer paso será cerrar el puerto por defecto:
# ufw deny 22
Luego abrir el nuevo puerto asignado:
# ufw allow puerto_elegido_enconfiguracion
Puede comprobar las reglas actuales con:
# ufw status
Reiniciar servidor SSH
Debe usar el comando:
# service sshd restart
Y reiniciar el firewall con:
# service ufw restart
Si todo va bien, ya deberíamos poder logearnos con el nuevo usuario creado.
También se podría comprobar que ya no sea posible conectarse con el usuario root.
Ahora el siguiente paso es la creación de la clave .pem.
Crear clave .pem
En el server comprobamos que exista el directorio .ssh dentro del home del usuario, la forma más rapida es intentar crear el mismo y ver que pasa o usar ls.
En nuestra computadora, usaremos el siguiente comando:
$ ssh-keygen -t rsa -b 4096
Pedirá el nombre para el archivo, este puede ser cualquiera, por ej pepa.
Nos pedirá definir una contraseña para el mismo (se recomienda definir una), que puede ser igual o diferente a la contraseña asociada al usuario.
Luego nos creará la clave privada y la pública, la privada la usaremos para iniciar sesión, la pública deberemos copiarla al directorio .ssh del usuario, por lo que podemos usar el comando scp, por ej:
El gestionar un servidor, nunca va a ser una tarea pasiva, y entre las tareas cotidianas, está el prestar atención a los logs.
Ya que son una fuente extra de información que nos permite tener un pantallazo del estado de situación del sistema.
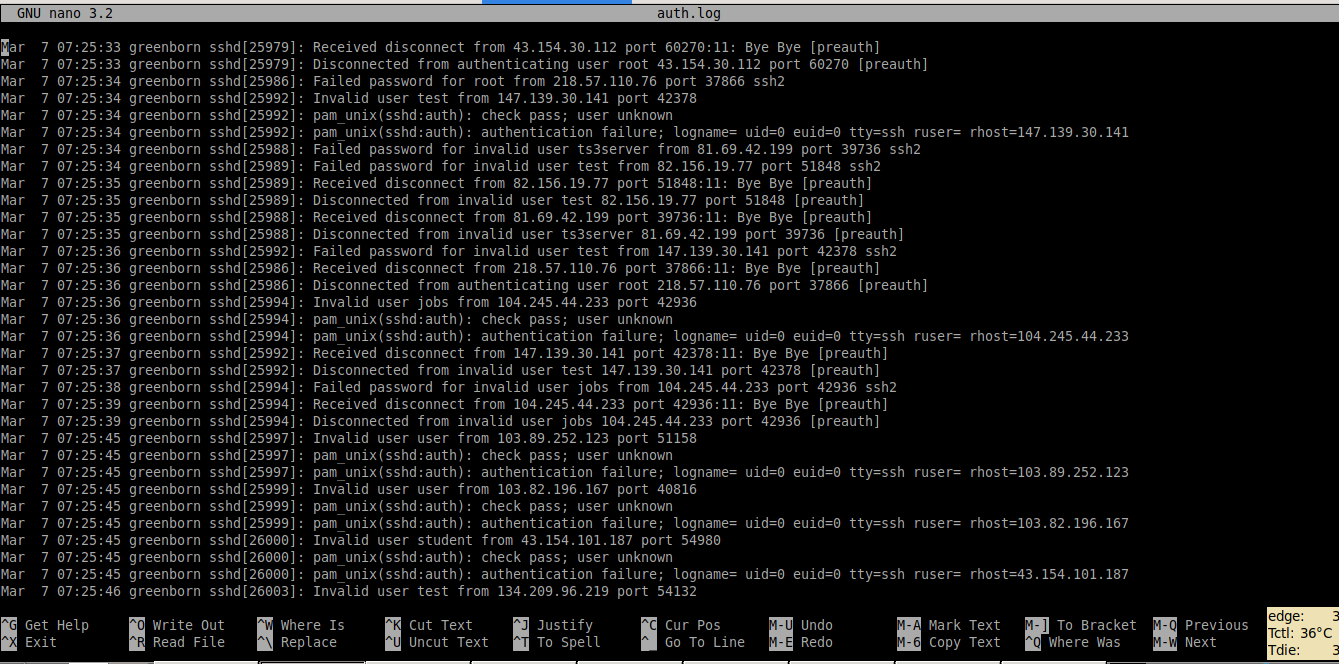
Uno de los archivos que conviene mirar de vez en cuando es el auth.log en donde se puede observar el registro de las sesiones iniciadas y los intentos de iniciar sesión.
Es claro que este archivo no nos permitiría saber si alguna persona no autorizada logró entrar, por que si nos basamos solo en ello alguien que quisiera tomar el control del sistema también se preocuparía en borrar las pruebas.
Igual no esta demás verificar el historial de accesos, ya sea con el buscador del Nano o con comandos como grep; no vaya a ser que alguno salte a la vista por haberse realizado en un horario en el cual uno no se haya conectado.
En ese caso nuestro intruso o bien sería vago, se olvidó de borrar su registro o algo más.
Igualmente no debería ser muy complicado realizar un control sobre la modificación del mismo a base de hashes o usar herramientas especializadas.
¿Y donde está ese archivo?
Bien si se trata de una distro Debian o sus derivados (desconozco la estructura de directorios que manejan otras distros).
Solo hay que ir a: /var/log
y allí estarán los auth.log, auth.log.1 y sus versiones comprimidas .gz, que tranquilamente se podrían analizar para tener una estadística de los intentos de acceso a los cuales esta siendo sometido el server.
En este caso hay entre 2 y 6 intentos de acceso por segundo! como se puede ver en la imagen de portada.
Esto muestra la importancia de no usar contraseñas débiles (lo ideal claves .pem), no permitir al acceso al usuario root, no tener puerto estándar (22) y actualizar las credenciales con periodicidad!.
Primeramente creo que debería decir, en que me baso para afirmar que existe cierto odio a PHP.
Tal vez la palabra odio no sea la más justa pero creo que a fin de cuentas llama más la atención.
Más que odio, seguramente se trate de desprecio, o de ridiculización, algo que nació como un meme y que más de uno toma como algo serio.
Como yo que ahora lo tomo en serio, pero el meme no nace de la nada, el meme es humor y el humor también puede tener una critica implícita.
El meme también es una forma de reírse de uno mismo y de reírse de las cosas que de una forma u otra nos afectan.
Y claramente siendo informático, y PHP una herramienta de trabajo (discusión aparte sería saber si se trata de una herramienta o no) es una cuestión que creo que me afecta a mí a todos los que trabajamos con dicho lenguaje de programación.
El problema, a por lo que entiendo, es que muchos memes apuntan hacia el desprecio.
Los memes de Cobol
Haciendo una búsqueda rápida en Google o Duck Duck Go, podemos ver algunos memes muy buenos sobre Cobol!
Se puede ver que en lineas generales lo que predomina es una valoración de lo antiguo del lenguaje.
Tal vez si se hiciera una votación para elegir una nueva mascota para lenguaje, un dinosaurio sea la elección natural.
Y no hay nada de malo en que sea viejo o antiguo, no todo lo nuevo es mejor.
Y no hay que perder de vista que el Software tiene como principal función la resolución de problemas, no ser algo nuevo o novedoso.
Después de todo, si algo funciona bien, ¿Para que tocarlo?
¿Cuando el Software se vuelve obsoleto?
Los memes de PHP
Bueno, ahora que pasa si uno busca “memes de PHP”?
Nos encontramos con cosas como estas:
Sin palabras…En serio? Programar en PHP es peor que vivir en la calle?¿Cómo puede ser que usar PHP lleve pegarse un tiro a si mismo y un framework especifico un parche que no mejora las cosas?Es PHP un nolenguaje de programación?Sin palabras…
Bueno, y hay muchos más memes, la idea tampoco es agregarlos a todos!
¿Por qué?
Por que tratar así a un lenguaje de programación? Se supone que como informáticos también deberíamos intentar ser objetivos, creo que PHP no se merece ser tratado así.
En términos de rendimiento es muy bueno, siendo muy buena competencia con respecto a otros lenguajes de programación.
A lo mejor está un poco flojo en el manejo de Web Sockets y consumo de RAM para algunos tipos de proyectos.
Pero está demostrado que es un lenguaje vivo en continuo desarrollo.
A cada versión mejora su rendimiento y consistencia en funciones propias del lenguaje.
Se mejora en cuestiones relacionadas al consumo de recursos y tengo la seguridad de que así seguirá avanzando.
Y sobre la seguridad, es cuestión de seguir las buenas practicas de programación.
Es un lenguaje no tipado, lo que en algunos escenarios podrían dar algunos problemas, pero eso se aplica a todos los lenguajes no tipados, no solo a PHP, JavaScript también tiene sus problemas.
Pero son cuestiones que con un poco de práctica y atención se pueden salvar.
¡Es totalmente injustificado odiar o despreciar PHP!